
Journal Papers

|
Lightweight Semantic-aided Localization with Spinning LiDAR Sensor
Yuan Ren, Ran Cheng, Christopher Agia, Bingbing Liu [Patent Submitted]. IEEE Transactions on Intelligent Vehicles (T-IV), 2021. paper We present a novel semantic enhanced LiDAR-based localization algorithm that considers a robust combination of semantic and non-semantic information, enabling adaptive scene-dependent localization behaviour. |
Conference Papers

|
Spotlights: Probing Shapes from Spherical Viewpoints
Jiaxin Wei, Lige Liu, Ran Cheng, Wenqing Jiang, Minghao Xu, Xinyu Jiang, Tao Sun, Soren Schwertfeger, Laurent Kneip ACCV, 2022. paper Inspired by spherical multi-view scanners, we propose a novel sampling model called Spotlights to represent a 3D shape as a compact 1D array of depth values. It simulates the configuration of cameras evenly distributed on a sphere, where each virtual camera casts light rays from its principal point through sample points on a small concentric spherical cap to probe for the possible intersections with the object surrounded by the sphere. |
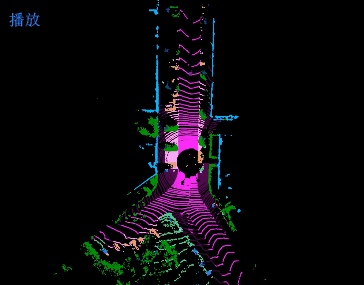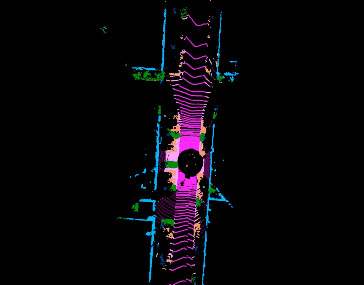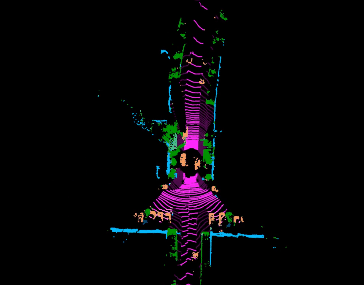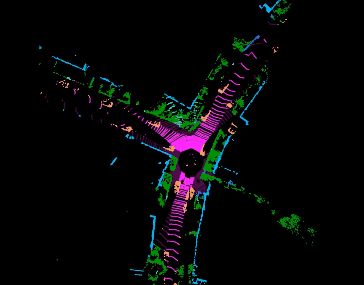
|
AF2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network
Ran Cheng, Ryan Razani, Ehsan Tagahvi, Enxu Li, Bingbing Liu CVPR, 2021. paper We optimized the network structure from S3Net and pushed our performance even further, and achieved state-of-the-art result on public dataset semanticKITTI dataset (sigle scan, named as AF2S3Net). |

|
[Oral] Lite-HDSeg: LiDAR Semantic Segmentation Using Lite Harmonic Dense Convolutions
Ryan Razani*, Ran Cheng*, Ehsan Tagahvi, Bingbing Liu * equal contribution ICRA, 2021. paper We proposed a real-time blazing fast Lite Harmonic Dense Block powered LiDAR point cloud segmentation network on spherical projected rangem map, and achieved state-of-the-art result on public dataset semanticKITTI dataset (sigle scan, named as LHDSegNet). |

|
[Oral] S3Net: A Sparse Semantic Segmentation Network
Ran Cheng, Ryan Razani, Yuan Ren, Bingbing Liu ICRA, 2021. paper video We proposed a novel sparse 3D convolutional neural network framework to tackle the large scale real-world point cloud semantic semantic segmentation chellenges and achieved state-of-the-art result on public dataset semanticKITTI dataset (named as kyber_HW). |

|
S3CNet: A Sparse Semantic Scene Completion Network
Ran Cheng, Christopher Agia, Yuan Ren, Xinghai Li, Bingbing Liu CoRL, 2020. paper We proposed a novel sparse 3D convolutional neural network framework to tackle the large scale real-world semantic scene completion chellenges and achieved state-of-the-art result on public dataset semanticKITTI dataset (named as Noah_Canada). |
|
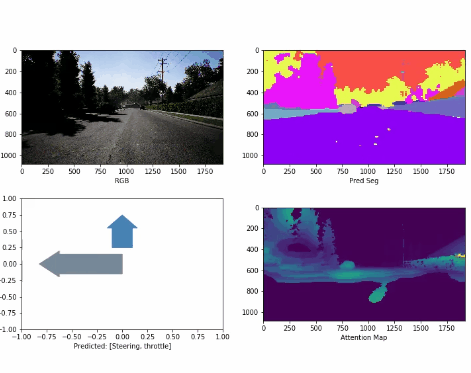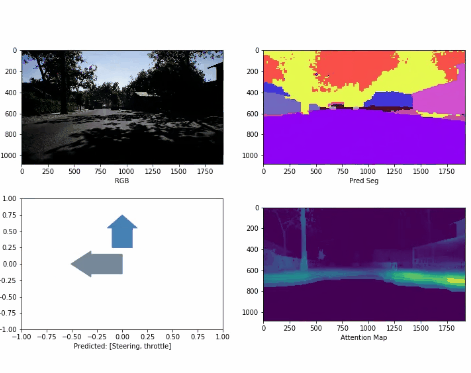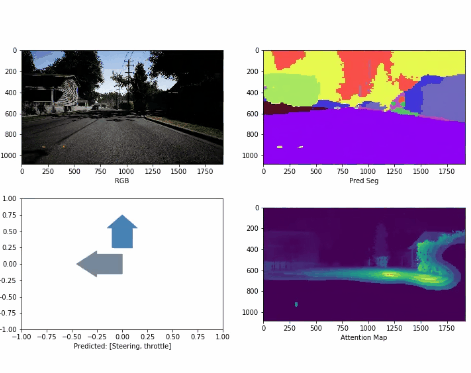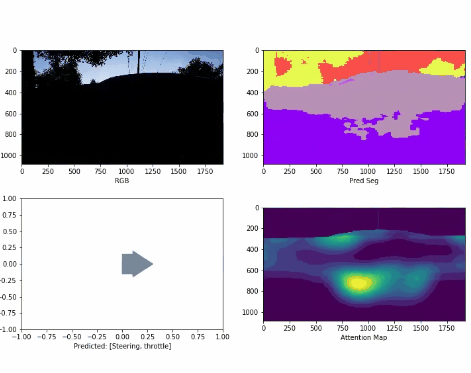
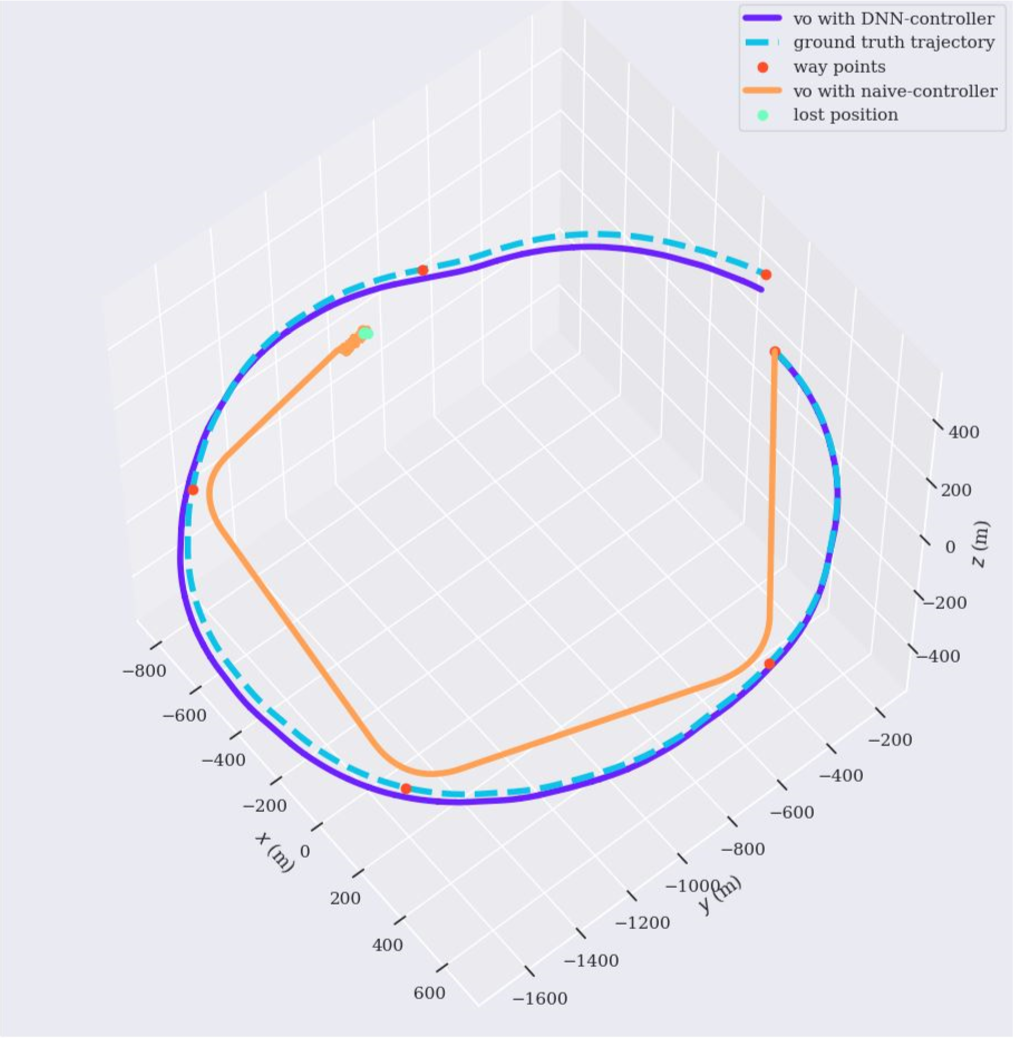
Attention-based Representations in Deep Reinforcement Learning for Autonomous Driving
Ran Cheng, Christopher Agia, Florian Shkurti, David Meger, Gregory Dudek Manuscript submitted to IROS, 2021. comming soon we propose a framework to inform and guide policy learning with augmented attention representations, demonstrating outstanding convergence speeds and stability for self-driving control. |

|
Depth Estimation for Monocular Direct Visual Odometry
Ran Cheng, Christopher Agia, David Meger, Gregory Dudek CRV, 2020. paper We incorporate dense depth prediction and propose a novel deep learning module to improve the robustness and precision for the traditional Direct Sparse Odometry method. |
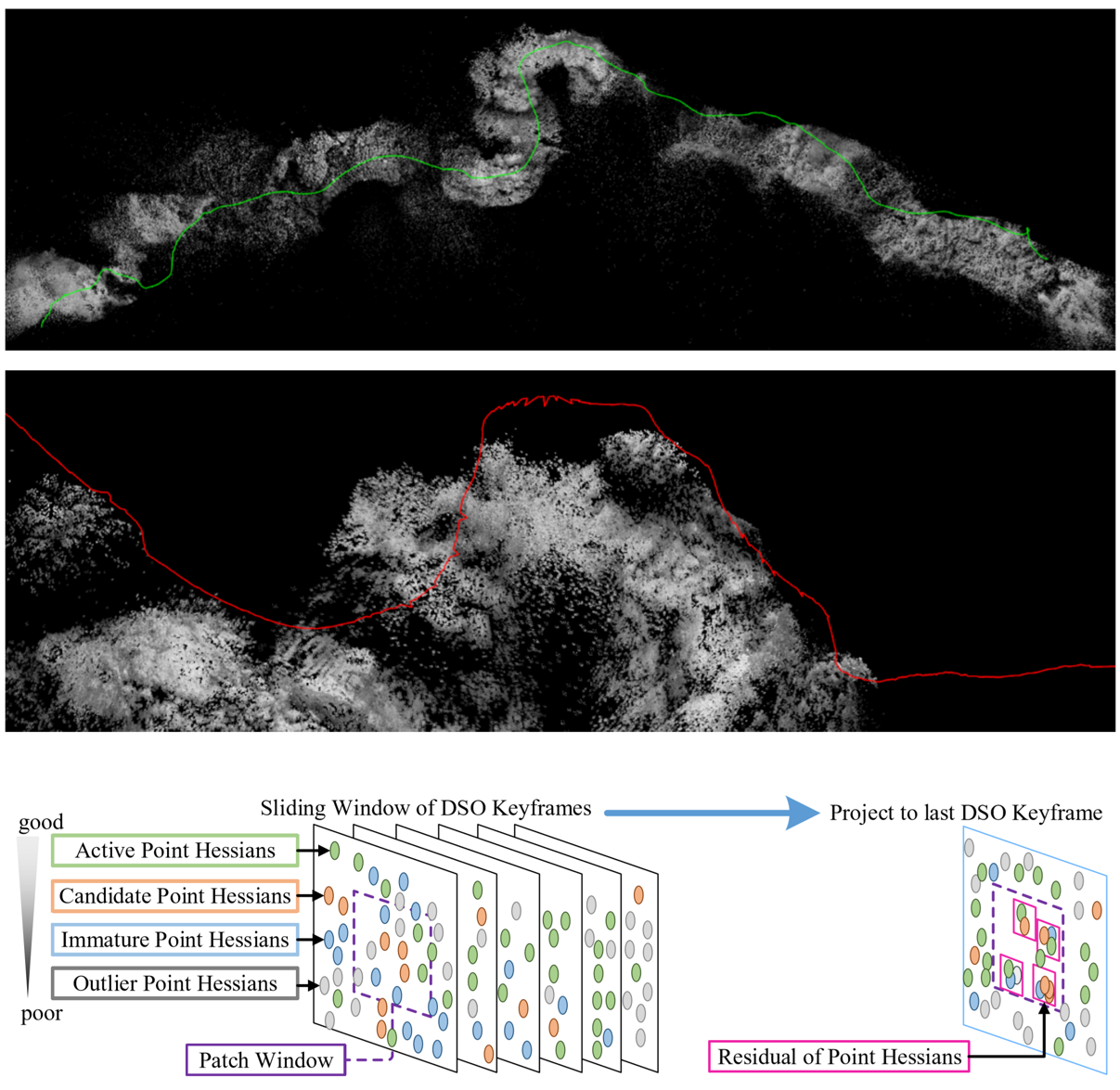
|
Vision-Based Autonomous Underwater Swimming in Dense Coral for Combined Collision Avoidance and Target Selection
Travis Manderson, Juan Higuera, Ran Cheng, Gregory Dudek IROS, 2018. paper Proposed a deep learning system enables safe and autonomous coral reef navigation in underwater environments. We validate our approach using an untethered and fully autonomous robot swimming through coral reef in the open ocean. |
|
Navigation in the Service of Enhanced Pose Estimation
Travis Manderson, Ran Cheng, David Meger, Gregory Dudek ISER, 2018. paper We modeled underwater visual navigation quality and turn it into training label for a deep synthetic network to guide robot swim along paths with low probability of visual tracking lost. |
Related Projects
|
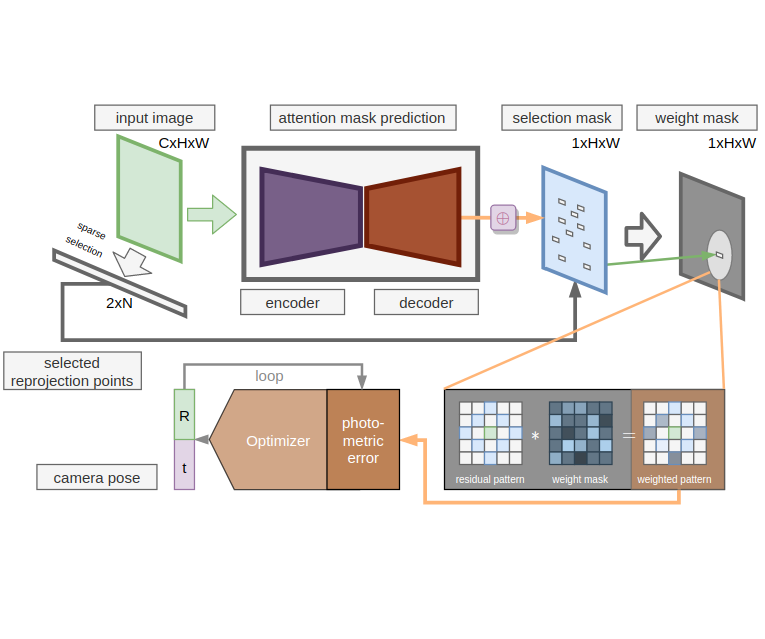
Deep Residual Pattern Learner for robust Direct Tracking
Ran Cheng, Christopher Agia Paper in preparation, 2020. We proposed a pipeline to weight residual pattern based on the residual point image local context to simulate the feature encoding and matching process in in-direct approaches. We are aiming to reduce the non-convexity introduced by including original image in energy function. |

|
Real-time Semantic Scene Completion
Christopher Agia, Ran Cheng Paper in preparation, 2020. We applied sparse convolution and transpose convolution on raw Kitti Velodyne point cloud data to predict dense semantic segmentation of BEV masks. |
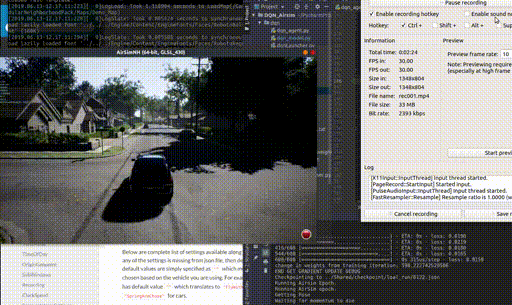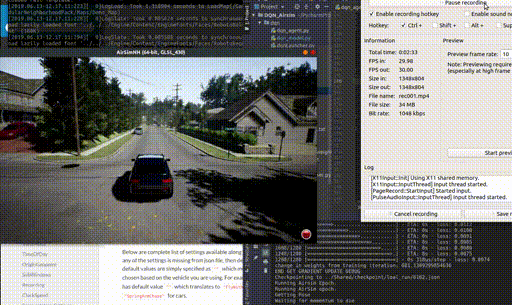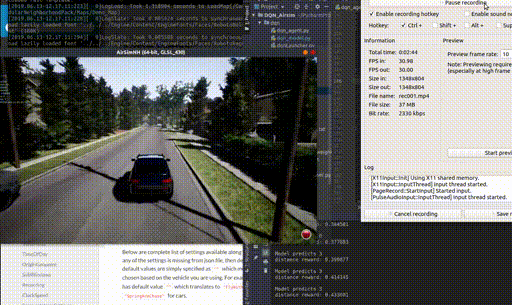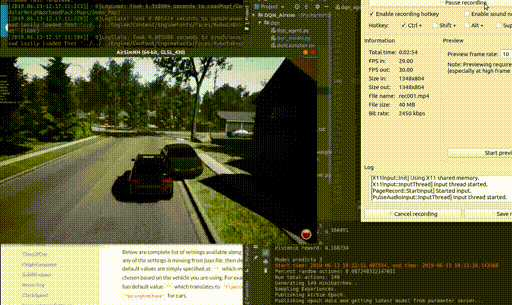
|
Deep Attention Augmented RL
Ran Cheng Paper in preparation, 2020. Learn to follow the lane in a complex environment with DQN and DDPG, augumented with the latent semantic input with raw rgb image. Experimental results demonstrated outstanding convergence rate and stability. |

|
[Patent Submitted] Topological Graph Map for 3D Lidar Localization and Mapping
Ran Cheng, Yuan Ren, Bingbing Liu Paper in Preparation, 2020. We proposed a 3D topological graph map to fit for large scale 3D Lidar localization. |

|
[Patent Submitted] Fast LiDAR Segmentation for Landmark-based Localization
Yuan Ren, Ran Cheng, Christopher Agia Paper in Preparation, 2020. We show the utility of a hybrid segmentation module to extract key LiDAR points for landmark-based localization, built upon a novel topological map structure. |

|
[Patent Submitted] Point Aggregation with Convolutional CRF for Long-Range Road Segmentation from LiDAR Point Clouds
Christopher Agia, Ran Cheng, Yuan Ren Paper in preparation, 2020. We propose an end-to-end convolutional network architecture for accurately segmenting road masks at extended ranges from LiDAR point clouds in real-time. |
Thesis
|
|
Depth estimation for monocular Direct Visual Odometry
Ran Cheng, David Meger, Gregory Dudek Master thesis, 2020. paper We exploit depth prediction as a candidate prior for the coarse initialization, tracking, and marginalization steps of the direct visual odometry system, enabling the second-order op-timizer to converge faster to a precise global minimum. In addition, the given depth prior supports large baseline stereo scenarios, maintaining robust pose estimation against chal-lenging motions such as in-place rotation. We further refine our pose estimation with semi-online loop closure. The experiments on KITTI demonstrate that our proposed method achieves state-of-the-art performance compared to both traditional direct visual odometry and learning-based counterparts |