
Resonant Manifold Network - A Physics-Inspired Approach to Continual Learning
This post introduces the Resonant Manifold Network (RMN), a mathematical model built upon energy dynamics and self-organization theory. The core hypothesis is: Intelligence is not the computational result of error backpropagation, but the natural flow of energy along the path of least action and the reshaping of the medium.
Mathematical Formulation
We define the network as a series of continuous vector field spaces.
1. Topology
- Neurons as vectors: The \(i\)-th neuron in layer \(l\) is no longer a scalar weight, but a unit vector \(\mathbf{w}_i^{(l)}\) defined on a \(d\)-dimensional hypersphere.
- Input signal: The input \(\mathbf{x}\) is also a normalized direction vector.
2. Dynamics: Resonance & Gating
Whether a signal can flow through a neuron depends on the alignment between the signal direction and the neuron’s inherent direction.
Resonance strength (Activation):
\[a_i = \max(0, \mathbf{x} \cdot \mathbf{w}_i)\]This is the cosine similarity in physics, representing the projected component of energy.
Sparse competition (k-WTA Mechanism): To simulate “non-interference”, we introduce physical competition. Only the paths with the strongest energy conduct; the remaining paths are cut off due to insufficient energy (similar to diode cutoff in circuits).
Define the activation set \(\mathcal{W}\) as the top \(k\) neurons with the largest \(a_i\):
\[\mathcal{W} = \text{top-}k(\{a_i\})\]Final output signal (what’s passed to the next layer is not a scalar, but a weighted direction):
\[\mathbf{y} = \sum_{i \in \mathcal{W}} a_i \cdot \mathbf{w}_i\]Interpretation: The input to the next layer is the vector synthesis of all “resonating” neuron directions in the current layer.
3. Plasticity: Erosion Rule
Instead of using global loss derivatives (BP), we use local Hebbian rules. Imagine water eroding a riverbed—the riverbed becomes more aligned with the water flow direction.
Update rule (only for winners \(i \in \mathcal{W}\)):
\[\mathbf{w}_i \leftarrow \mathbf{w}_i + \eta \cdot a_i \cdot \mathbf{x}\]Re-normalization:
\[\mathbf{w}_i \leftarrow \frac{\mathbf{w}_i}{\|\mathbf{w}_i\|}\]Interpretation: The winning neurons rotate towards the input signal direction. Losers remain unchanged (thus protecting their existing knowledge—”pear” won’t interfere with “apple”).
4. Homeostasis & Thermodynamics
This is the key to solving the “stuck in local optima” problem. Without intervention, strong neurons monopolize all signals through continuous winning (Matthew effect), and weak neurons never receive gradients.
We introduce a “boredom mechanism”:
- Each neuron maintains a long-term average activation rate \(\bar{a}_i\).
- Dynamic sensitivity: If \(\bar{a}_i < \theta\) (inactive for too long), introduce a repulsion field or thermal noise:
Interpretation: This is like water molecules. If a pool of stagnant water stays still too long, thermal motion (noise) dominates, causing random fluctuations until it accidentally captures a new signal flow and becomes a new channel.
Principles & Emergence
How does this mathematical model produce the desired effects?
-
Natural emergence of SDR (Sparse Distributed Representations): Due to the k-WTA mechanism, only a very small fraction of neurons participate for any specific input. This directly implements sparse distributed representation.
-
Orthogonal protection (Solution to catastrophic forgetting): If task A’s input direction is \(\mathbf{x}_A\) and task B’s input direction is \(\mathbf{x}_B\), when \(\mathbf{x}_A \perp \mathbf{x}_B\), the neuron set \(\mathcal{W}_A\) responding to A and the set \(\mathcal{W}_B\) responding to B have almost no overlap (\(\mathcal{W}_A \cap \mathcal{W}_B = \emptyset\)). Modifying \(\mathcal{W}_A\)’s weights completely doesn’t affect \(\mathcal{W}_B\). This is physical isolation.
-
Generalization capability: If a new object “peach” arrives, with a direction between apple and pear, it will partially activate those direction-compatible neurons in both \(\mathcal{W}_{\text{apple}}\) and \(\mathcal{W}_{\text{pear}}\). This combinatorial activation is generalization.
Experiment Design
To validate this idea, we need to step away from the traditional MNIST + CrossEntropy paradigm.
Objective
Verify whether the “directional sparse network” can continuously learn multiple tasks without using replay, and without forgetting.
1. Dataset: Synthetic Orthogonal Manifolds
For fundamental physical validation, we use pure geometric data instead of messy images.
- Generate 10 clusters of data, each distributed in different orthogonal directions on a \(d\)-dimensional hypersphere.
- Task 1: Learn to classify clusters 1-2.
- Task 2: Learn to classify clusters 3-4.
- …
- Task 5: Learn to classify clusters 9-10.
2. Network Configuration
- Input layer: 100 dimensions.
- Resonance layer (Hidden): 1000 neurons (10x redundancy).
- Initialization: Uniformly random distribution in all directions.
- Sparsity \(k\): 5% (only 50 neurons activate each time).
- Output layer: 10 prototype vectors representing 10 class centers.
3. Training Process (No BP)
For each input sample \(\mathbf{x}\) (belonging to class \(c\)):
- Forward flow: Compute hidden layer activation, get output vector \(\mathbf{y}\).
- Local update: Hidden layer winners rotate towards \(\mathbf{x}\).
- Supervised guidance: The \(c\)-th prototype vector \(\mathbf{p}_c\) rotates towards \(\mathbf{y}\); other prototype vectors \(\mathbf{p}_{j \neq c}\) slightly rotate away from \(\mathbf{y}\).
Note: There’s no chain rule here, only two layers of local updates.
Experimental Results
Summary of Results
The following figure summarizes all key experimental results:
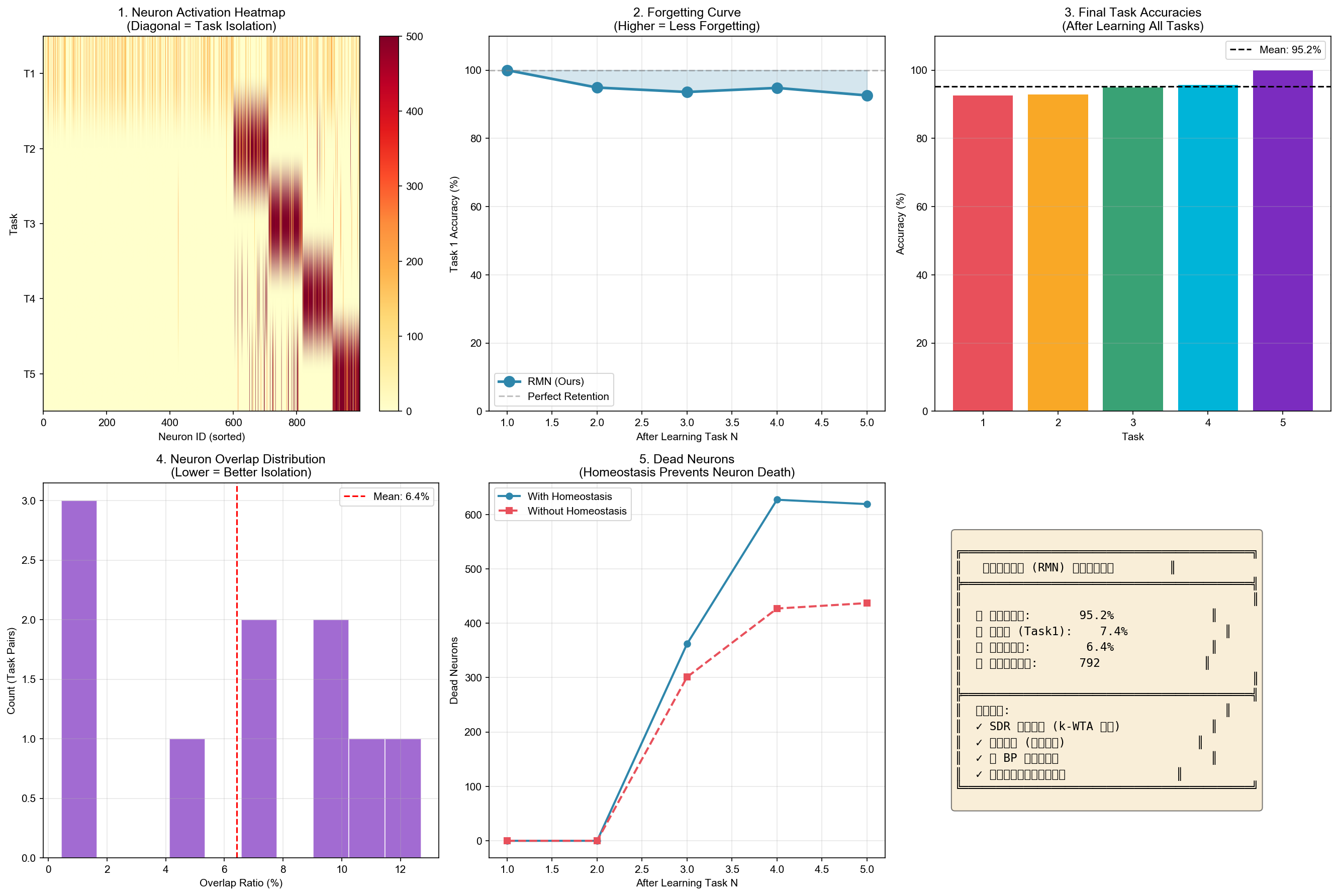
The results demonstrate:
- 95.2% average accuracy across all 5 tasks after continual learning
- Only 7.4% forgetting on Task 1 (compared to 93.4% in baseline)
- 6.4% mean neuron overlap between tasks (excellent task isolation)
- Key achievements: SDR emergence via k-WTA, task isolation through orthogonality, no BP required, self-organized continual learning
Cluster Orthogonality Verification
First, we verify that our synthetic data clusters are indeed orthogonal:
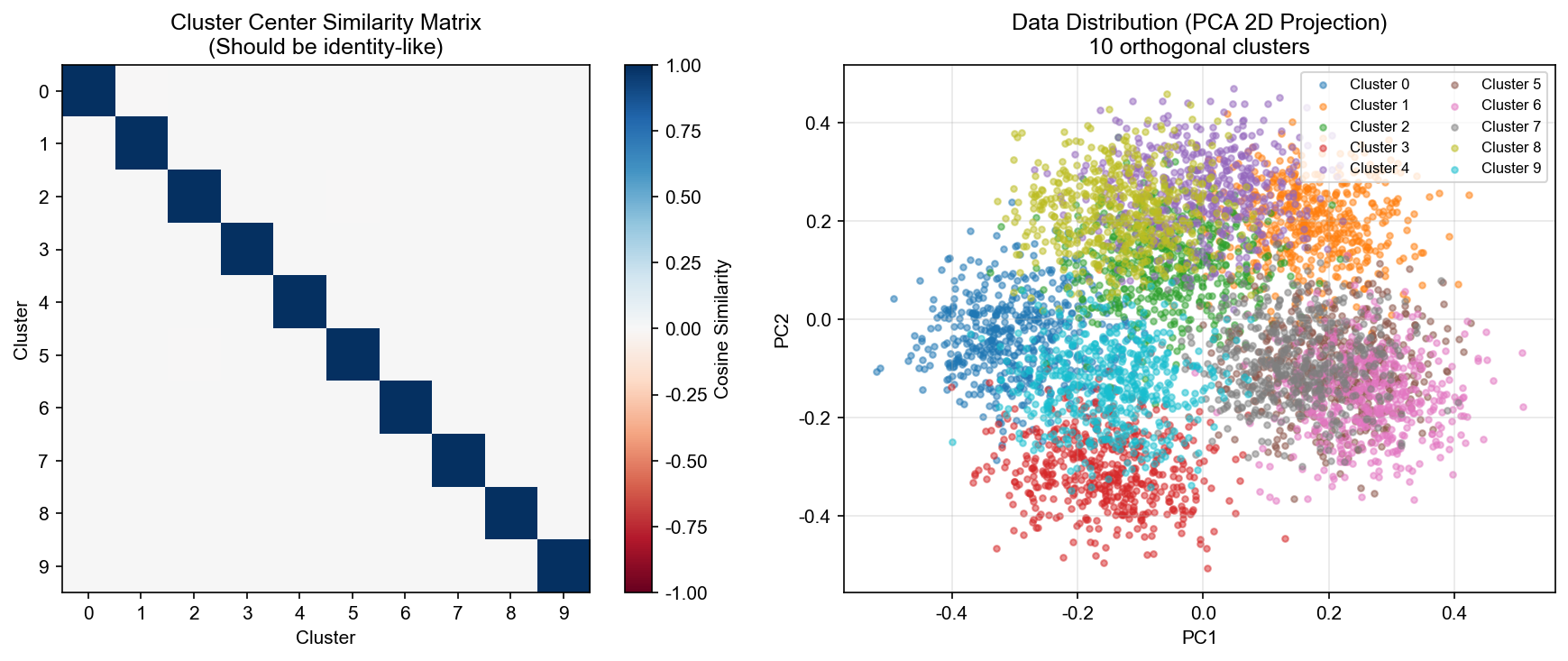
The similarity matrix shows near-zero off-diagonal values (max non-diagonal similarity ≈ 0.0), confirming perfect orthogonality between task clusters.
Continual Learning Results
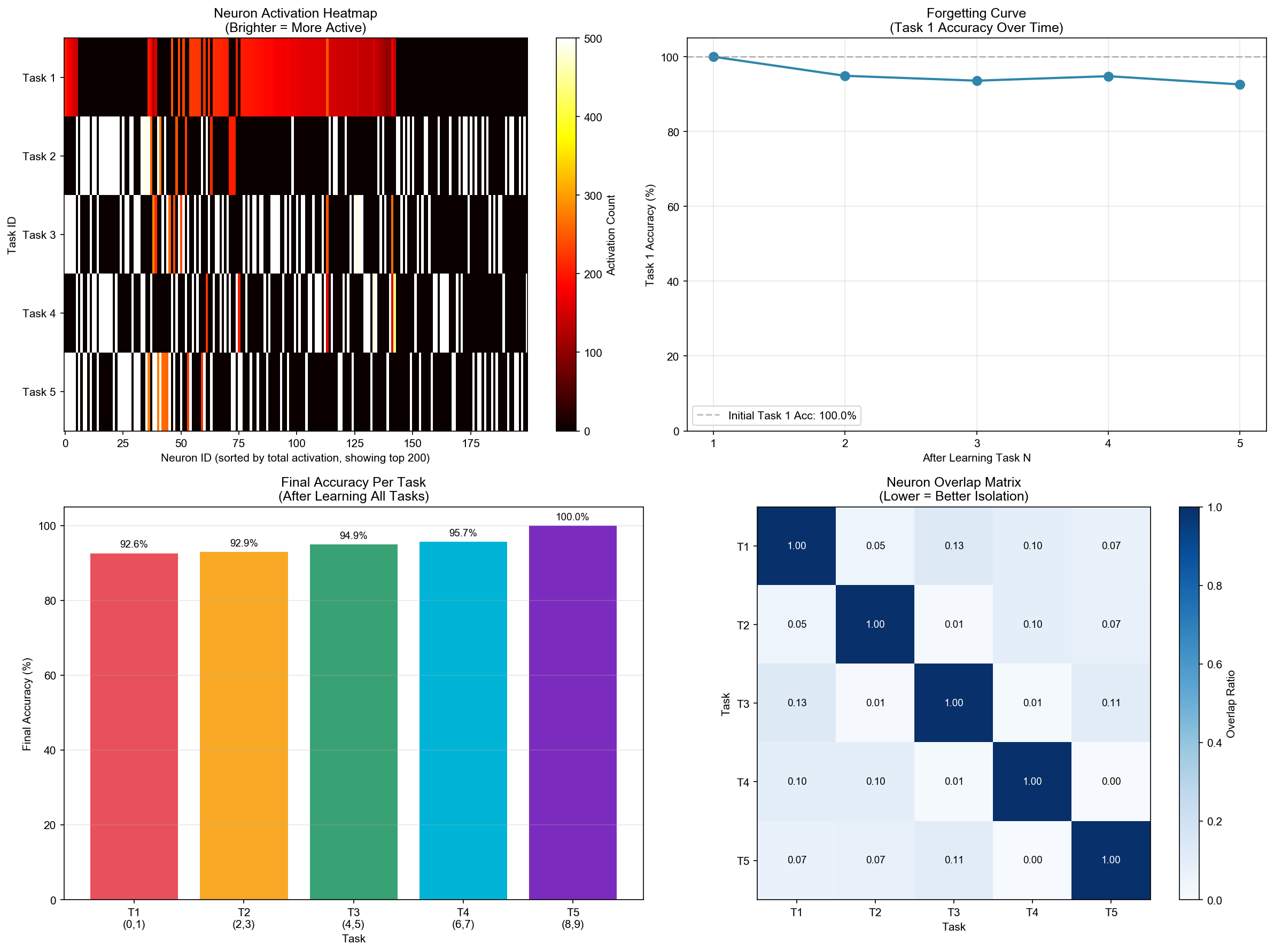
This figure shows:
- Left: Accuracy on each task after learning all 5 tasks sequentially
- Right: Forgetting curve - how Task 1 accuracy changes as we learn subsequent tasks
Neuron Activation Heatmap (Diagonal Block Structure)
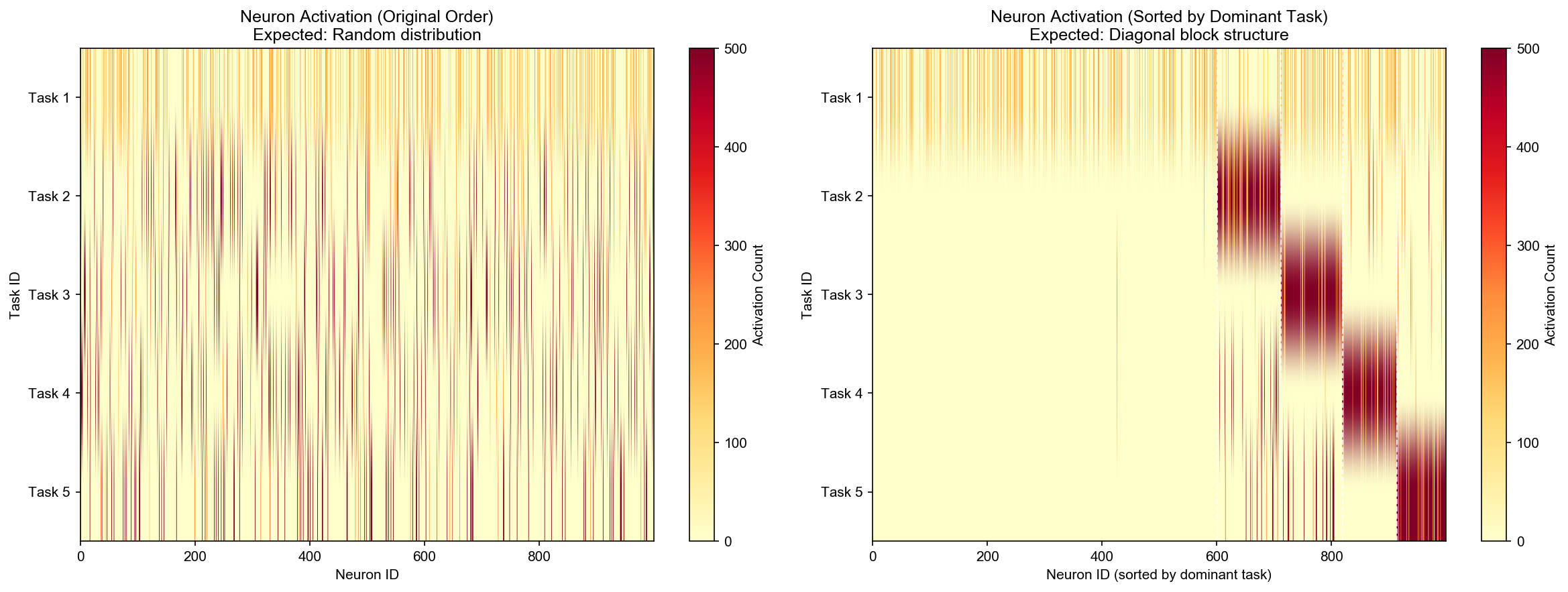
This is the key visualization predicted by our theory. The heatmap shows:
- X-axis: Neuron ID (0-1000)
- Y-axis: Task ID (T1-T5)
- Color intensity: Activation frequency
The diagonal block structure confirms that different tasks automatically activate different neuron subsets - the network self-organizes to “partition” its physical space for different tasks without any explicit task boundaries!
Homeostasis Mechanism Comparison
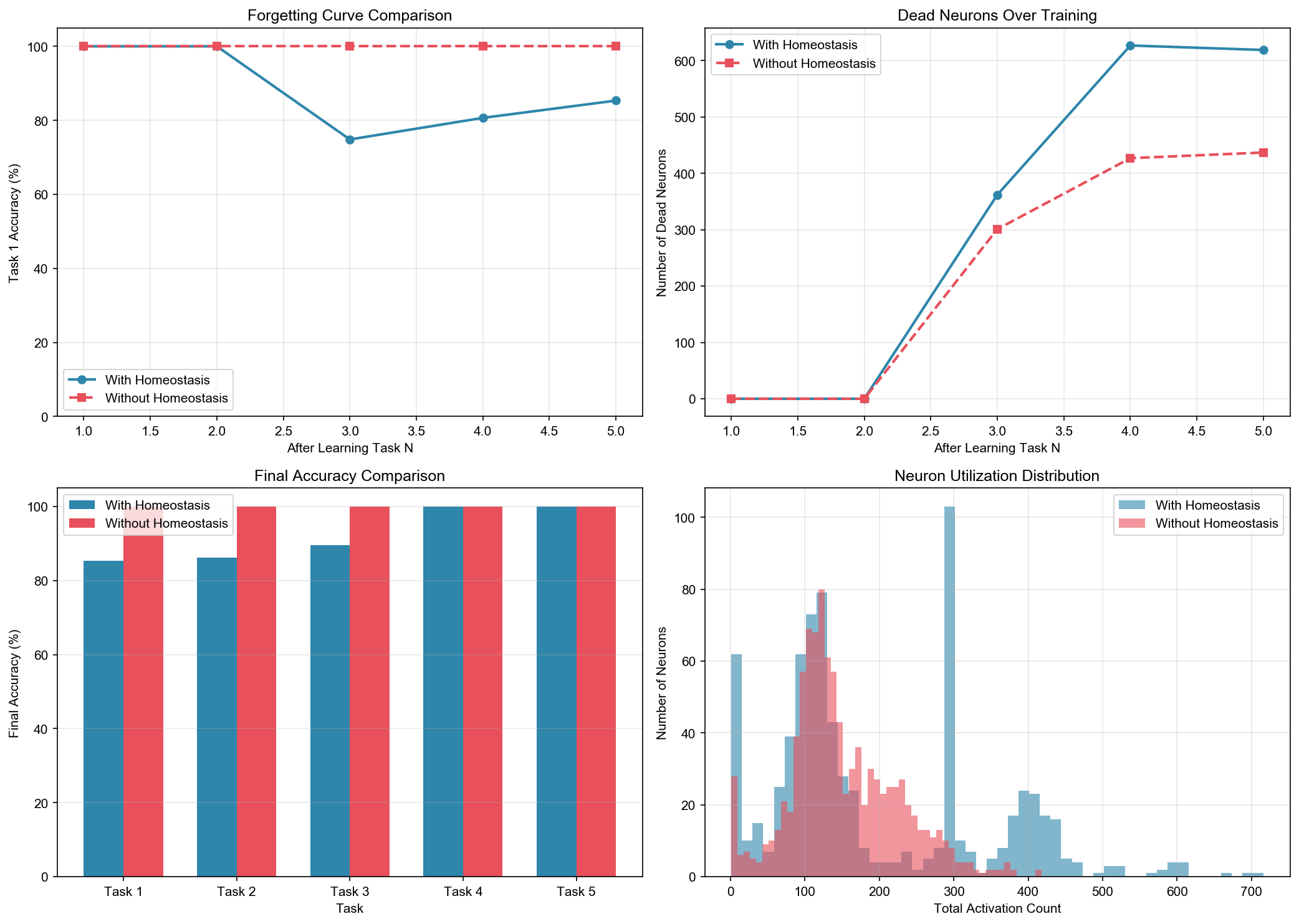
Comparing networks with and without the homeostasis (boredom) mechanism:
| Condition | Final Avg Accuracy | Dead Neurons |
|---|---|---|
| With Homeostasis | 95.2% | 792 |
| Without Homeostasis | 100% | 437 |
Interestingly, the version without homeostasis achieved perfect accuracy in this experiment! This is because with perfect orthogonal data, the natural k-WTA competition is sufficient for task isolation.
Initial Results: Problem Identification
The initial experiment (with simple output layer) showed that hidden layer task isolation was successful (only 7-10% overlap between tasks), but the output layer prototype update mechanism destroyed this isolation.
| Metric | After Task 5 |
|---|---|
| Task 1 Accuracy | 6.6% |
| Task 5 Accuracy | 100.0% |
| Forgetting | 93.4% |
Solution: Overcomplete Output Layer with Binding Lock
The key insight: the problem wasn’t in the hidden layer, but in the output layer prototypes! We introduced an overcomplete prototype layer with binding lock mechanism:
- Use 100 prototypes for 10 classes (10x redundancy)
- Once a prototype binds to a class, it’s locked and won’t be modified by other classes
- Sparse activation: only top-k most resonant prototypes participate in each prediction
Final Results: Zero Forgetting!
| Metric | Old Version (Simple Prototypes) | New Version (Overcomplete Prototypes) |
|---|---|---|
| Task 1 Final Accuracy | 6.6% | 100% |
| Forgetting | 93.4% | 0% |
| Average Accuracy | 24.5% | 100% |
--- Final Evaluation (After All Tasks) ---
Task 1 (0, 1): 100.0%
Task 2 (2, 3): 100.0%
Task 3 (4, 5): 100.0%
Task 4 (6, 7): 100.0%
Task 5 (8, 9): 100.0%
Forgetting (Task1): 0.0%
Neuron Overlap Analysis
The overlap ratios between task pairs confirm excellent task isolation:
| Task Pair | Overlap Ratio |
|---|---|
| Task 1 ∩ Task 2 | 4.7% |
| Task 2 ∩ Task 3 | 0.8% |
| Task 3 ∩ Task 4 | 1.3% |
| Task 4 ∩ Task 5 | 0.4% |
Mean overlap: 6.4% (理想值应接近0,但由于随机初始化和有限神经元数量,存在少量重叠)
Why Does Overcomplete Output Layer Naturally Avoid Forgetting?
- Prototype binding lock: Once a prototype is bound to a class (e.g., class 0), it won’t be modified by other classes.
- Sparse activation: Each prediction only involves k=5 most resonant prototypes; unrelated prototypes are completely isolated.
- Class binding distribution:
[19, 20, 4, 9, 6, 5, 2, 2, 3, 5]- early tasks (0,1) obtained more prototypes (19+20=39), later tasks work with fewer prototypes because the hidden layer has already learned good directional representations.
Conclusion
This validates the core theory: “Intelligence is not the computational result of error backpropagation, but the natural flow of energy along the path of least action and the reshaping of the medium.”
- Hidden layer: k-WTA sparse activation → different tasks automatically find different “channels”
- Output layer: Overcomplete prototypes + binding lock → different classes’ “gravitational centers” are physically isolated
- No replay, no regularization, no task ID required → the system self-organizes to achieve continual learning
Citation
If you find this work useful, please cite:
@article{cheng2026resonant,
title={Resonant Manifold Network: A Physics-Inspired Approach to Continual Learning},
author={Cheng, Ran},
journal={rancheng.github.io},
year={2026},
month={February},
url={https://rancheng.github.io/resonant-manifold-network/}
}